Руководство Java OutputStreamWriter
1. OutputStreamWriter
OutputStreamWriter - это подкласс Writer, это мост, который позволяет преобразовать byte stream в character stream, или, другими словами, он позволяет преобразовать OutputStream в Writer.
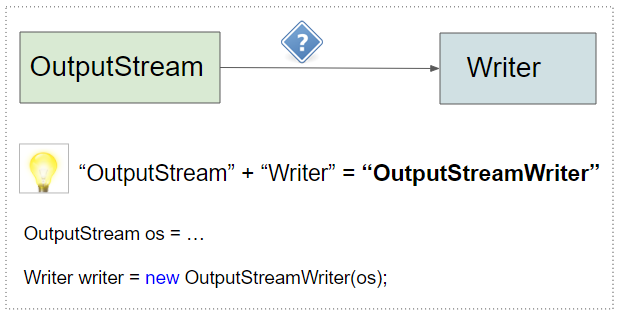
Совет: Чтобы преобразовать "OutputStream" в "Writer", вам просто нужно объединить эти два слова для формирования "OutputStreamWriter", и вы получите решение.
OutputStreamWriter constructors
OutputStreamWriter(OutputStream out)
OutputStreamWriter(OutputStream out, String charsetName)
OutputStreamWriter(OutputStream out, Charset cs)
OutputStreamWriter(OutputStream out, CharsetEncoder enc)Помимо методов, унаследованных от родительского класса, OutputStreamWriter имеет несколько других собственных методов.
Method | Description |
String getEncoding() | Возвращает имя кодировки символов, используемой OutputStreamWriter. |
2. UTF-16 OutputStreamWriter
UTF-16 довольно распространенная кодировка (encoding) для китайского или японского текста. В этом примере мы проанализируем, как написать файл с использованием кодировки UTF-16.
Вот содержимое для записи в файл:
JP日本-八洲В этом примере мы используем UTF-16OutputStreamWriter для записи символов в файл, а затем используем FileInputStream для чтения каждого byte этого файла.
OutputStreamWriter_UTF16_Ex1.java
package org.o7planning.outputstreamwriter.ex;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.nio.charset.StandardCharsets;
public class OutputStreamWriter_UTF16_Ex1 {
private static final String filePath = "/Volumes/Data/test/utf16-file-out.txt";
public static void main(String[] args) throws IOException {
System.out.println(" --- Write UTF-16 File --- ");
write_UTF16_Character_Stream();
System.out.println(" --- Read File as Binary Stream --- ");
readAs_Binary_Stream();
}
private static void write_UTF16_Character_Stream() throws IOException {
File outFile = new File(filePath);
outFile.getParentFile().mkdirs(); // Create parent folder.
// Create OutputStream to write a file.
OutputStream os = new FileOutputStream(outFile);
// Create a OutputStreamWriter
OutputStreamWriter osw = new OutputStreamWriter(os, StandardCharsets.UTF_16);
String s = "JP日本-八洲";
osw.write(s);
osw.close();
}
private static void readAs_Binary_Stream() throws IOException {
InputStream is = new FileInputStream(filePath);
int byteValue;
while ((byteValue = is.read()) != -1) { // Read byte by byte.
System.out.println((char) byteValue + " " + byteValue);
}
is.close();
}
}Output:
--- Write UTF-16 File ---
--- Read File as Binary Stream ---
þ 254
ÿ 255
0
J 74
0
P 80
e 101
å 229
g 103
, 44
0
- 45
Q 81
k 107
m 109
2 50В Java, тип данных char имеет размер 2 bytes, а UTF-16 используется для кодирования String. На рисунке ниже показаны символы в OutputStreamWriter:
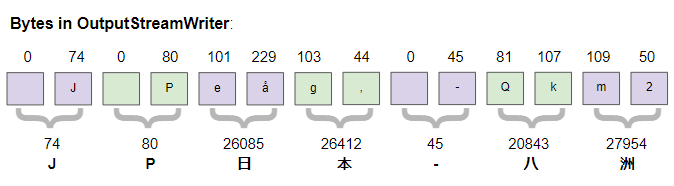
Из анализа bytes на созданном файле следует отметить: первые 2 bytes(254, 255) используются для обозначения того, что это кодированный текст UTF-16. Они также известны как BOM (Byte Order Mark), а следующие bytes совпадают с bytes в OutputStreamWriter.

3. UTF-8 OutputStreamWriter
UTF-8 - самая популярная кодировка (encoding) в мире. Она может кодировать все письмености мира, включая китайские иероглифы и японские иероглифы. Начиная с Java5, UTF-8 является кодировкой по умолчанию для чтения и записи файлов.
Файлы UTF-8, созданные Java, не имеют BOM (Byte Order Mark) (Первые bytes файла, которые помечают его как UTF-8).
OutputStreamWriter_UTF8_Ex1.java
package org.o7planning.outputstreamwriter.ex;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.nio.charset.StandardCharsets;
public class OutputStreamWriter_UTF8_Ex1 {
private static final String filePath = "/Volumes/Data/test/utf8-file-out.txt";
public static void main(String[] args) throws IOException {
System.out.println(" --- Write UTF-8 File --- ");
write_UTF8_Character_Stream();
System.out.println(" --- Read File as Binary Stream --- ");
readAs_Binary_Stream();
}
private static void write_UTF8_Character_Stream() throws IOException {
File outFile = new File(filePath);
outFile.getParentFile().mkdirs(); // Create parent folder.
// Create OutputStream to write a file.
OutputStream os = new FileOutputStream(outFile);
// Create a OutputStreamWriter
OutputStreamWriter osw = new OutputStreamWriter(os, StandardCharsets.UTF_8);
String s = "JP日本-八洲";
osw.write(s);
osw.close();
}
private static void readAs_Binary_Stream() throws IOException {
InputStream is = new FileInputStream(filePath);
int byteValue;
while ((byteValue = is.read()) != -1) { // Read byte by byte.
System.out.println((char) byteValue + " " + byteValue);
}
is.close();
}
}Output:
--- Write UTF-8 File ---
--- Read File as Binary Stream ---
J 74
P 80
æ 230
151
¥ 165
æ 230
156
¬ 172
- 45
å 229
133
« 171
æ 230
´ 180
² 178В Java тип данных char имеет размер 2 bytes, а UTF-16 используется для кодирования String. На рисунке ниже показаны символы в OutputStreamWriter:
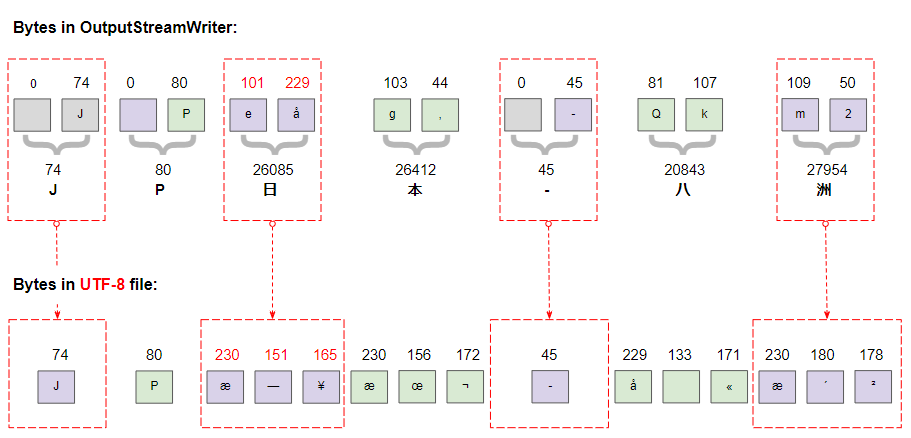
UTF-8 кодируется гораздо сложнее, чем UTF-16, он использует 1, 2, 3 или 4bytes для хранения символа. Детальный анализ bytes во созданном файле UTF-8 ясно показывает это.
Number of bytes | From | To | Byte 1 | Byte 2 | Byte 3 | Byte 4 | ||
1 | U+0000 | 0 | U+007F | 127 | 0xxxxxxx | |||
2 | U+0080 | 128 | U+07FF | 2047 | 110xxxxx | 10xxxxxx | ||
3 | U+0800 | 2048 | U+FFFF | 65535 | 1110xxxx | 10xxxxxx | 10xxxxxx | |
4 | U+10000 | 65536 | U+10FFFF | 1114111 | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
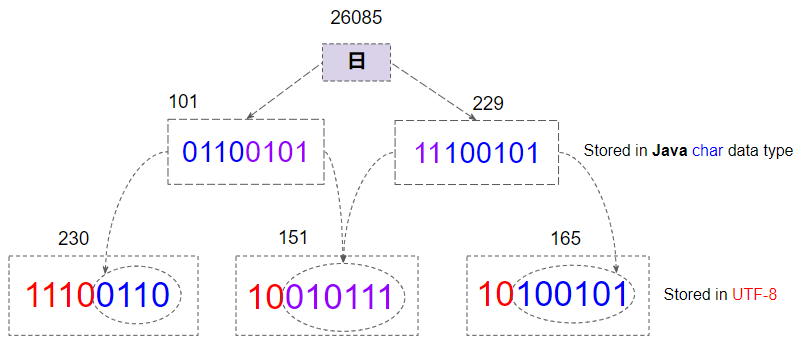
Например, символ "日" имеет код 26085, в диапазоне [2048,65535], UTF-8 для его хранения требуется 3 bytes.
Руководства Java IO
- Руководство Java CharArrayWriter
- Руководство Java FilterReader
- Руководство Java FilterWriter
- Руководство Java PrintStream
- Руководство Java BufferedReader
- Руководство Java BufferedWriter
- Руководство Java StringReader
- Руководство Java StringWriter
- Руководство Java PipedReader
- Руководство Java LineNumberReader
- Руководство Java PushbackReader
- Руководство Java PrintWriter
- Руководство Java IO Binary Streams
- Руководство Java IO Character Streams
- Руководство Java BufferedOutputStream
- Руководство Java ByteArrayOutputStream
- Руководство Java DataOutputStream
- Руководство Java PipedInputStream
- Руководство Java OutputStream
- Руководство Java ObjectOutputStream
- Руководство Java PushbackInputStream
- Руководство Java SequenceInputStream
- Руководство Java BufferedInputStream
- Руководство Java Reader
- Руководство Java Writer
- Руководство Java FileReader
- Руководство Java FileWriter
- Руководство Java CharArrayReader
- Руководство Java ByteArrayInputStream
- Руководство Java DataInputStream
- Руководство Java ObjectInputStream
- Руководство Java InputStreamReader
- Руководство Java OutputStreamWriter
- Руководство Java InputStream
- Руководство Java FileInputStream
Show More