Руководство Java IdentityHashMap
1. IdentityHashMap
IdentityHashMap<K,V> является классом в Фреймворке коллекции Java (Java Collection Framework), который реализует интерфейс Map<K,V>. IdentityHashMap полностью поддерживает все функции, указанные в интерфейсе Map, включая дополнительные функции. В основном IdentityHashMap очень похож на HashMap, они используют метод хеширования (hashing technique) для улучшения доступа к данным и производительности хранения. Однако они отличаются тем, как хранятся данные и как сравниваются ключи (key). IdentityHashMap использует оператор == для сравнения двух ключей, в то время как HashMap использует метод equals.
public class IdentityHashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, java.io.Serializable, Cloneable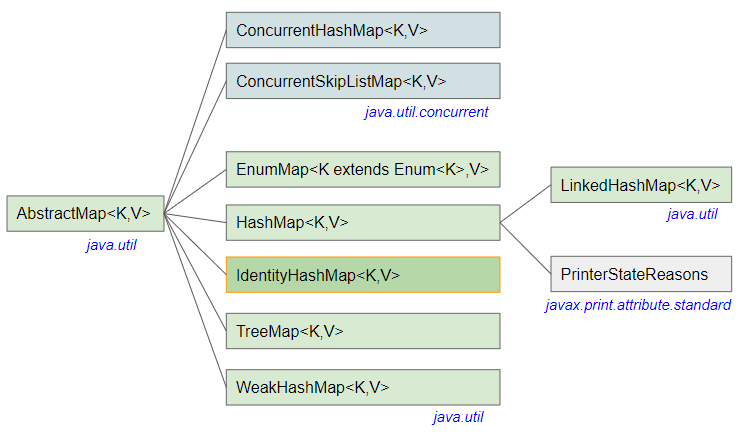
- Map
- HashMap
- LinkedHashMap
- TreeMap
- WeakHashMap
- EnumMap
- ConcurrentHashMap
- ConcurrentSkipListMap
IdentityHashMap constructors:
IdentityHashMap() |
Создает пустой объект IdentityHashMap с максимальным ожидаемым размером по умолчанию (21).
|
IdentityHashMap(int expectedMaxSize) |
Создает пустой объект IdentityHashMap с заданным максимальным ожидаемым размером. Добавление большего, чем ожидалось, сопоставления expectedMaxSize в IdentityHashMap приведет к росту внутренней структуры данных, что может занять немного времени.
|
IdentityHashMap(Map<? extends K,? extends V> m) |
Создает объект IdentityHashMap с отображениями, скопированными с указанной Map.
|
2. Как работает IdentityHashMap?
Как и HashMap, разработчики Java использовали метод хеширования (hashing technique) для класса IdentityHashMap для улучшения доступа к данным и производительности хранения. Теперь мы посмотрим, как этот метод используется в IdentityHashMap. В основном мы анализируем, что происходит, когда мы вызываем методы IdentityHashMap.put(K,V), IdentityHashMap.get(K) и IdentityHashMap.remove(key).
IdentityHashMap управляет массивом объектов (Object[] table), размер которого может автоматически увеличиваться по мере необходимости. И пары (key,value) хранятся в позициях (idx,idx+1).
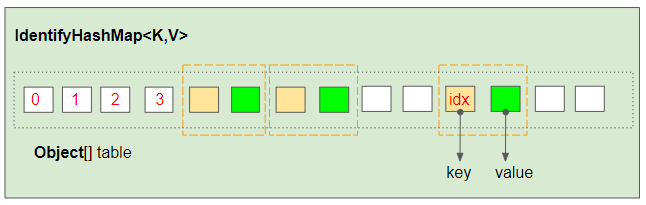
Длина внутреннего массива рассчитывается на основе максимального ожидаемого размера IdentityHashMap, как показано в примере ниже:
InternalArrayLength_test.java
package org.o7planning.identityhashmap.ex;
public class InternalArrayLength_test {
private static final int MINIMUM_CAPACITY = 4;
private static final int MAXIMUM_CAPACITY = 1 << 29;
private static int capacity(int expectedMaxSize) {
// assert expectedMaxSize >= 0;
return (expectedMaxSize > MAXIMUM_CAPACITY / 3) ? MAXIMUM_CAPACITY
: (expectedMaxSize <= 2 * MINIMUM_CAPACITY / 3) ? MINIMUM_CAPACITY
: Integer.highestOneBit(expectedMaxSize + (expectedMaxSize << 1));
}
public static void main(String[] args) {
for (int i = 1; i < 15; i++) {
int mapSize = i * 25;
int arrayLength = 2 * capacity(mapSize);
System.out.printf("Map size: %3d --> Internal Array length: %d%n",mapSize, arrayLength);
}
}
}Output:
Map size: 25 --> Internal Array length: 128
Map size: 50 --> Internal Array length: 256
Map size: 75 --> Internal Array length: 256
Map size: 100 --> Internal Array length: 512
Map size: 125 --> Internal Array length: 512
Map size: 150 --> Internal Array length: 512
Map size: 175 --> Internal Array length: 1024
Map size: 200 --> Internal Array length: 1024
Map size: 225 --> Internal Array length: 1024
Map size: 250 --> Internal Array length: 1024
Map size: 275 --> Internal Array length: 1024
Map size: 300 --> Internal Array length: 1024
Map size: 325 --> Internal Array length: 1024
Map size: 350 --> Internal Array length: 2048IdentityHashMap.put(key,value):
При вызове метода IdentityHashMap.put(key,value),IdentityHashMap определит ожидаемую позицию для хранения пары (notNullKey,value) во внутреннем массиве, используя следующую формулу:
private static int hash(Object x, int length) {
int h = System.identityHashCode(x);
// Multiply by -127, and left-shift to use least bit as part of hash
return ((h << 1) - (h << 8)) & (length - 1);
}
// Return default not null Object if key is null.
private static Object maskNull(Object key) {
return (key == null ? NULL_KEY : key);
}
final Object notNullKey = maskNull(key);
int len = table.length; // Length of Object[] table.
int idx = hash(notNullKey, len);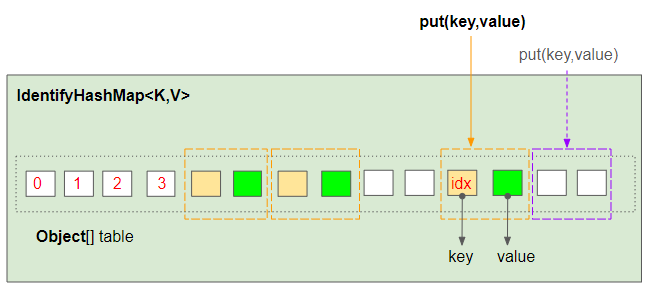
Ожидается, что пара (notNullKey,value) будет храниться в позиции (idx,idx+1) массива. (С idx, рассчитанным по приведенной выше формуле).
- Если table[idx] имеет значение null,то пара (notNullKey,value) будет храниться в (idx,idx+1) позиции массива.
- В другом случае, если ключ table[idx]==notNullKey имеет значение true, то value будет присвоено table[idx+1].
- В противном случае отображение (notNullKey,value) будет храниться в (idx+2,idx+3) или (idx+4,idx+5)....
IdentityHashMap.get(key):
При вызове метода IdentityHashMap.get(key), IdentityHashMap определит ожидаемую позицию, найденную сопоставлением с ключом notNullKey во внутреннем массиве, используя ту же формулу:
private static int hash(Object x, int length) {
int h = System.identityHashCode(x);
// Multiply by -127, and left-shift to use least bit as part of hash
return ((h << 1) - (h << 8)) & (length - 1);
}
// Return default not null Object if key is null.
private static Object maskNull(Object key) {
return (key == null ? NULL_KEY : key);
}
final Object notNullKey = maskNull(key);
int len = table.length; // Length of Object[] table.
int idx = hash(notNullKey, len);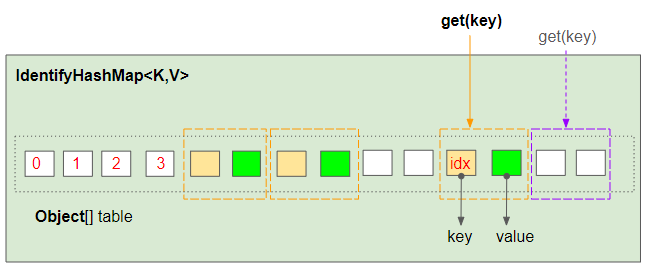
Ожидается, что сопоставление с ключом notNullKey будет найдено в индексе idx массива. IdentityHashMap использует оператор == для сравнения ключа notNullKey и table[idx].
// true or false?
notNullKey == table[idx]Если notNullKey == table[idx] имеет значение true, то метод вернет table[idx+1]. В противном случае notNullKey будет сравниваться со следующими элементами в индексах idx+2, idx+4,... до тех пор, пока соответствующий индекс не будет найден или не достигнет конца массива. Если он не найден, метод вернет значение null.
IdentityHashMap.remove(key):
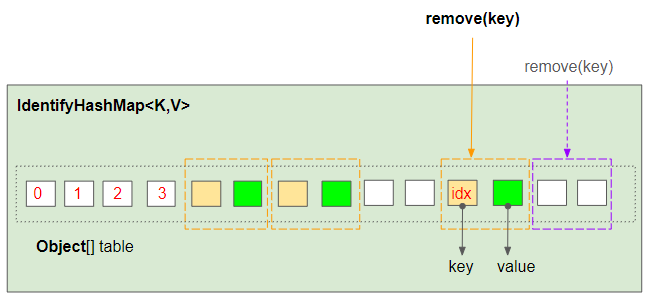
Метод IdentityHashMap.remove(key) работает аналогично методу IdentityHashMap.get(key). Если будут найдены позиции (index,index+1) удаляемых сопоставлений, они будут обновлены до null.
table[index] = null;
table[index+1] = null;Вывод:
IdentityHashMap использует статический метод System.identityHashCode(key) для вычисления hashcode ключа. В основном этот метод возвращает целое число, которое очень редко дублируется. Метод, используемый в IdentityHashMap, помогает повысить производительность доступа и хранения данных. Сократите использование оператора == для сравнения объектов.
См. Подробнее о методе хеширования (hashing technique), используемом в HashMap:
3. Examples
IdentityHashMapEx1.java
package org.o7planning.identityhashmap.ex;
import java.util.IdentityHashMap;
public class IdentityHashMapEx1 {
public static void main(String[] args) {
String key1 = "Tom";
String key2 = new String("Tom");
// key1 == key2 ? false
System.out.println("key1 == key2 ? " + (key1== key2)); // false
IdentityHashMap<String, String> map = new IdentityHashMap<String, String>();
map.put(key1, "Value 1");
map.put(key2, "Value 2");
System.out.println("Map Size: " + map.size());
System.out.println(map);
}
}Output:
key1 == key2 ? false
Size: 2
{Tom=Value 1, Tom=Value 2}В принципе, все функции IdentityHashMap соответствуют спецификации интерфейса Map, за исключением того, что он использует оператор == для сравнения ключей, что является незначительным нарушением спецификации интерфейса Map (требуется метод equals для сравнения ключей).
См. дополнительные примеры:
Руководства Java Collections Framework
- Руководство Java PriorityBlockingQueue
- Руководство Java Collections Framework
- Руководство Java SortedSet
- Руководство Java List
- Руководство Java Iterator
- Руководство Java NavigableSet
- Руководство Java ListIterator
- Руководство Java ArrayList
- Руководство Java CopyOnWriteArrayList
- Руководство Java LinkedList
- Руководство Java Set
- Руководство Java TreeSet
- Руководство Java CopyOnWriteArraySet
- Руководство Java Queue
- Руководство Java Deque
- Руководство Java IdentityHashMap
- Руководство Java WeakHashMap
- Руководство Java Map
- Руководство Java SortedMap
- Руководство Java NavigableMap
- Руководство Java HashMap
- Руководство Java TreeMap
- Руководство Java PriorityQueue
- Руководство Java BlockingQueue
- Руководство Java ArrayBlockingQueue
- Руководство Java TransferQueue
Show More