Использование Java JSoup для анализа кода HTML
1. Что такое Jsoup?
Jsoup это Java HTML Parser. Сказать по-другому, Jsoup это библиотека использованная для анализа документа HTML. Jsoup предоставляет API для получения и манипулирования данными из URL или из файлов HTML. Использует методы похожие на DOM, CSS , JQuery чтобы получить данные и манипулировать ими.

Посмотрим пример с Jsoup:
HelloJsoup.java
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class HelloJsoup {
public static void main( String[] args ) throws IOException{
Document doc = Jsoup.connect("http://eclipse.org").get();
String title = doc.title();
System.out.println("Title : " + title);
}
}2. Библиотека Jsoup
Вы можете использовать Maven или скачать библиотеку Jsoup файла формата jar.
С maven:
<!-- http://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.8.3</version>
</dependency>Или можете скачать:
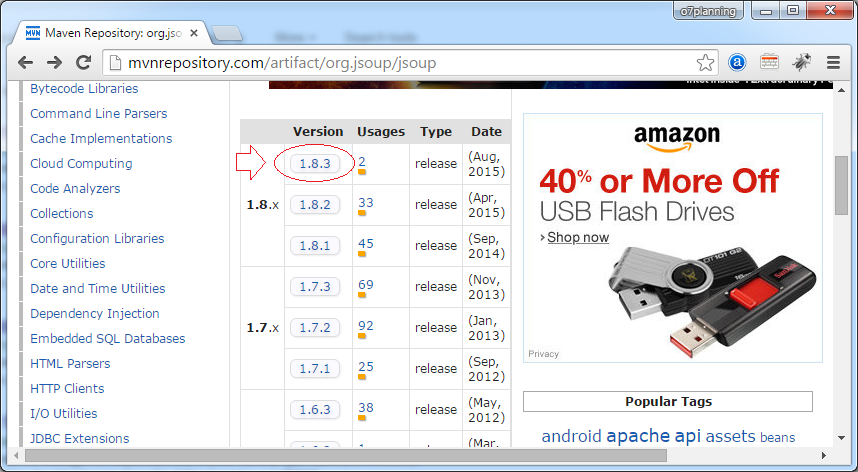
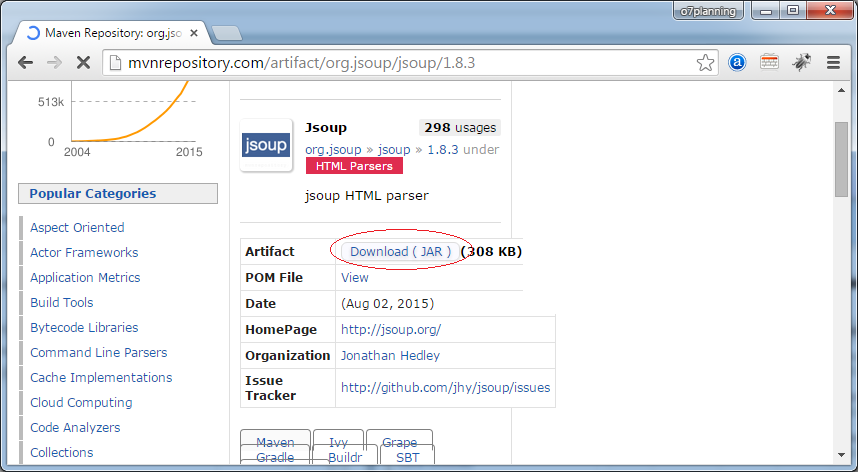
3. Jsoup API
Jsoup включает много классов, но есть 3 самых важных класса, включает:
- org.jsoup.Jsoup
- org.jsoup.nodes.Document
- org.jsoup.nodes.Element
- Jsoup.java
Метод | Описание |
static Connection connect(String url) | Создает и возвращает объект Connection подключенный к URL. |
static Document parse(File in, String charsetName) | Анализирует файл документа HTML с определением charset . |
static Document parse(File in, String charsetName, String baseUri) | Анализирует файл документа HTML с определением charset, и baseUri. |
static Document parse(String html) | Анализирует код HTML и возвращает объект Document. |
static Document parse(String html, String baseUri) | Анализирует код HTML с baseUri в объект Document. |
static Document parse(URL url, int timeoutMillis) | Анализирует URL в Document. |
static String clean(String bodyHtml, Whitelist whitelist) | Возвращает безопасный HTML из введенного HTML, с помощью анализа введенного HTML и фильтрует через белый список (Whitelist) разрешенных тегов и атрибутов. |
- Document.java
Методы | Описание |
Element body() |
Доступ в элемент body документа HTML |
Charset charset() |
Возвращает charset использованный в данном документе
|
void charset(Charset charset) |
Настраивает charset используемый для данного документа.
|
Document clone() |
Создает версью copy данного документа, включая copy всех дочерних node.
|
Element createElement(String tagName) |
Создает новый элемент
|
static Document createShell(String baseUri) |
Создает пустой документ (Document), подходящий для добавления элементов.
|
Element head() |
Доступ к элементам head.
|
String location() |
Возвращает URL данного документа.
|
String nodeName() |
Возвращает node name данного node.
|
Document normalise() |
Нормализирует документ.
|
String outerHtml() |
Возвращает Outer HTML данного node.
|
Document.OutputSettings outputSettings() |
Возвращает объект настройки вывода для данного документа.
|
Document outputSettings(Document.OutputSettings outputSettings) |
Настраивает вывод для документа.
|
Document.QuirksMode quirksMode() | |
Document quirksMode(Document.QuirksMode quirksMode) | |
Element text(String text) |
Настраивает содержание текста (text) в body данного документа.
|
String title() |
Возвращает содержание заголовка документа.
|
void title(String title) |
Настраивает содержание заголовка документа.
|
boolean updateMetaCharsetElement() |
Возвращает true если элемент (element) с информацией charset в данном документе обновлен через метод Document.charset(Charset). |
void updateMetaCharsetElement(boolean update) |
Настраивает да или нет, этот элемент (element) с информацией charset обновленный через метод Document.charset(Charset).
|
- Element.java
4. Манипулирование документом
Создать Document из URL
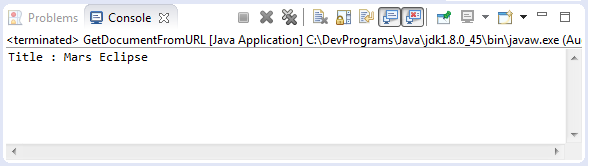
GetDocumentFromURL.java
package org.o7planning.tutorial.jsoup.document;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class GetDocumentFromURL {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("http://eclipse.org").get();
String title = doc.title();
System.out.println("Title : " + title);
}
}Запуск примера:
Создать Document из File
GetDocumentFromFile.java
package org.o7planning.tutorial.jsoup.document;
import java.io.File;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class GetDocumentFromFile {
public static void main(String[] args) throws IOException {
File htmlFile = new File("C:/index.html");
Document doc = Jsoup.parse(htmlFile, "UTF-8");
String title = doc.title();
System.out.println("Title : " + title);
}
}Создать Document из String
GetDocumentFromString.java
package org.o7planning.tutorial.jsoup.document;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class GetDocumentFromString {
public static void main(String[] args) throws IOException {
String htmlString = "<html><head><title>Simple Page</title></head>"
+ "<body>Hello</body></html>";
Document doc = Jsoup.parse(htmlString);
String title = doc.title();
System.out.println("Title : " + title);
System.out.println("Content:\n");
System.out.println(doc.toString());
}
}Запуск примера:
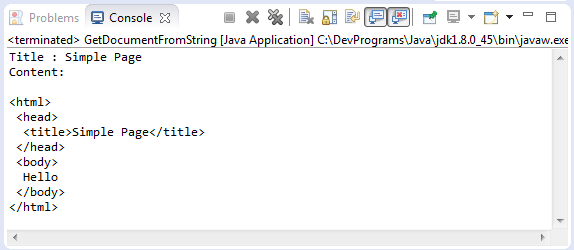
Парсинг фрагмента HTML
Полный документ HTML включает Header и Body, иногда вам нужно сделать парсинг фрагмента HTML. И вы можете получить полный дркумент HTML включая header & body. Посмотрим пример:
ParsingBodyFragment.java
package org.o7planning.tutorial.jsoup.document;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ParsingBodyFragment {
public static void main(String[] args) throws IOException {
String htmlFragment = "<h1>Hi you!</h1><p>What is this?</p>";
Document doc = Jsoup.parseBodyFragment(htmlFragment);
String fullHtml = doc.html();
System.out.println(fullHtml);
}
}Запуск примера:
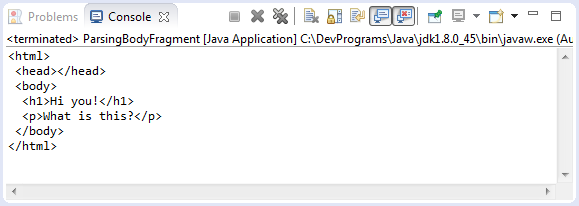
5. Методы DOM
Jsoup имеет некоторые методы почти похожие с методами в моделе DOM (Модель парсинга документа XML)
Метод | Описание |
Element getElementById(String id) | Поиск элемента данный ID, включая или внизу данного элемента. |
Elements getElementsByTag(String tag) | Поиск элементов, включая и рекурсивно внизу данного элемента, с определенным названием тега. |
Elements getElementsByClass(String className) | Поиск элемента с classNam данный параметром, включая или внизу данного элемента. |
Elements getElementsByAttribute(String key) | Поиск элементов с атрибутами данные параметром, не отличая прописные и строчные буквы. |
Elements siblingElements() | Возвращает братские элеметы текущего элемента. |
Element firstElementSibling() | Возвращает первый братский элемент текущего элемента. |
Element lastElementSibling() | Возвращает последний братский элемент текущего элемента. |
...... | |
Методы получения данных на Element.
Метод | Описание |
String attr(String key) | Возвращает значение атрибута данный key этого элемента. |
void attr(String key, String value) | Настроить значение атрибута. Если атрибут существет, он будет заменен. |
String id() | Возвращает атрибут ID, если есть, или возвращает пустой string если нет. |
String className() | Возвращает строку значения атрибута "class", может содержать много class name, отделенные пробелами. (Например<div class="header gray"> возвращает "header gray") |
Set<String> classNames() | Возвращает все class names. Например <div class="header gray">, возвращает набор 2 элементов "header" и "gray". Заметьте, редактирование в данном наборе не меняет атрибут элемента. Если вы хотите изменить используйте метод classNames(java.util.Set). |
String text() | Возвращает сочетание текста и всех текстов подэлементов. |
void text(String value) | Настроить текст для данного элемента. |
String html() | Возвращает String в HTML внутри данного тега. Например <div><p>a</p> возвращает <p>a</p>. (Node.outerHtml() возвратит <div><p>a</p></div>.) |
void html(String value) | Настроить Html внутри данного элемента. Удалить все готовые HTML внутри. |
Tag tag() | Возвращает Tag этому элементу. |
String tagName() | Возвращает название тега данного элемента. Например div. |
...... | |
Методы манипулирования HTML:
Методы | Описание |
Element append(String html) | Соединяет HTML в данный элемент. Html предоставлен и будет проанализирован, и node будут соединены в конце дочерних node данного элемента. |
Element prepend(String html) | Соединяет HTML в данный элемент. Html предоставлен и будет проанализирован, и node будут соединены в начале дочерних node данного элемента. |
Element appendText(String text) | Создает и соединяет новый TextNode в данный элемент. |
Element prependText(String text) | Создает и соединяет новый TextNode в начале дочерних node данного элемента. |
Element appendElement(String tagName) | Создает новый элемент данный tag name. И соединяет его в конце как подэлемент. |
Element prependElement(String tagName) | Создает новый элемент данный tag name. И соединяет его в начале как подэлемент. |
Element html(String value) | Настраивает html внутри данного элемента. Удаляет все готовые Html внутри. |
...... | |
Например, использовать методы DOM, сделать парсинг документа HTML написать информацию тега form.
register.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Register</title>
</head>
<body>
<form id="registerForm" action="doRegister" method="post">
<table>
<tr>
<td>User Name</td>
<td><input type="text" name="userName" value="Tom" /></td>
</tr>
<tr>
<td>Password</td>
<td><input type="password" name="password" value="Tom001" /></td>
</tr>
<tr>
<td>Email</td>
<td><input type="email" name="email" value="theEmail@gmail.com" /></td>
</tr>
<tr>
<td colspan="2"><input type="submit" name="submit" value="Submit" /></td>
</tr>
</table>
</form>
</body>
</html>ReadHtmlForm.java
package org.o7planning.tutorial.jsoup.dom;
import java.io.File;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class ReadHtmlForm {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.parse(new File("files/register.html"), "utf-8");
Element form = doc.getElementById("registerForm");
System.out.println("Form action = "+ form.attr("action"));
Elements inputElements = form.getElementsByTag("input");
for (Element inputElement : inputElements) {
String key = inputElement.attr("name");
String value = inputElement.attr("value");
System.out.println(key + " = " + value);
}
}
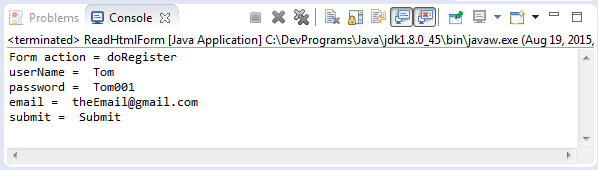
}Запуск примера:
GetAllLinks.java
package org.o7planning.tutorial.jsoup.dom;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class GetAllLinks {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("http://o7planning.org").get();
// Elements extends ArrayList<Element>.
Elements aElements = doc.getElementsByTag("a");
for (Element aElement : aElements) {
String href = aElement.attr("href");
String text = aElement.text();
System.out.println(text);
System.out.println("\t" + href);
}
}
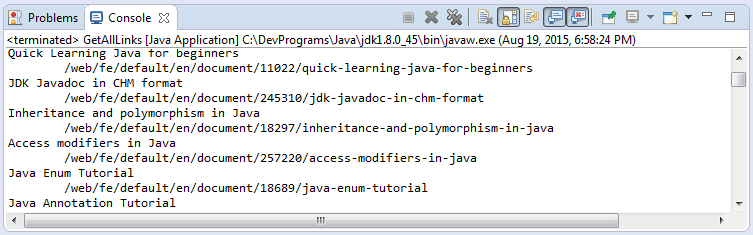
}Запуск примера:
6. Методы индентичные Css, jQuery
Вы хотите найти или воспользоваться элементами используя синтаксисом похожим на CSS или jQuery?
JSoup предоставляет вам некоторые методы для того, чтобы сделать это:
- Element.select(String selector)
- Elements.select(String selector)
Например:
Connection conn = Jsoup.connect("http://o7planning.org");
Document doc = conn.get();
// a with href
Elements links = doc.select("a[href]");
// img with src ending .png
Elements pngs = doc.select("img[src$=.png]");
// div with class=masthead
Element masthead = doc.select("div.masthead").first();
// direct a after h3
Elements resultLinks = doc.select("h3.r > a");Элементы JSoup поддерживают синтаксис похожий на CSS (или JQuery) помогающий вам найти соответствующие элементы. Такие поддержки очень сильны. Методы выбора есть наготове в классе Document, Element или Elements.
Обзор Selector (Селектор).
Селектор | Описание |
tagname | Искать элементы по тегу. Например: a |
ns|tag | Искать элементы по тегу в пространстве имент (namespace), например fb|name значит найти элементы <fb:name> |
#id | Искать элементы по ID, например #logo |
.class: | Искать элементы по названию класса, например .masthead |
[attribute] | Элементы с атрибутами, например [href] |
[^attr] | Элементы с атрибутами с приставкой, например [^data-] искать элементы с атрибутами начинающимися на data- |
[attr=value] | Элементы со значениями атрибута, например [width=500] (Можно использовать ковычки) |
[attr^=value], [attr$=value], [attr*=value] | Элементы со значениями атрибута, начинающиеся, заканчивающиеся, или содержащие значение, например [href*=/path/] |
[attr~=regex] | Элементы со значениями совпадающими с регулярным выражением, например img[src~=(?i)\.(png|jpe?g)] |
* | Все элементы, например * |
Комбинации Selector
Selector | Описание |
el#id | Элементы с ID, например div#logo |
el.class | Элементы с классом, например div.masthead |
el[attr] | Элементы с атрибутом, например a[href] |
например a[href].highlight | |
ancestor child | (Родительский элемент - наследованный элемент) Подэлементы родительского элемента, например . .body p ищет элемент p везде под блоком с классом "body" |
parent > child | Прямые элементы наследники родительского элемента, например div.content > p найти элементы p которые являются прямыми наследниками div имеющие class ='content'; и body > * найти прямые подэлементы тега body |
siblingA + siblingB | Найти элементы братья B сразу перед элементом A, например div.head + div |
siblingA ~ siblingX | Найти элементы братья X перед элементом A, например h1 ~ p |
el, el, el | Группа с разными Selector, ищет элементы подходящие к одному из Selector; например div.masthead, div.logo |
Pseudo selectors
Selector | Описание |
:lt(n) | Поиск элементов с родственным индексом (местоположение в дереве DOM связь с родтельским элементом) меньше n; например td:lt(3) |
:gt(n) | Поиск элементов с родственным индексом больше n, например div p:gt(2) |
:eq(n) | Поиск элементов с родственным индексом равным n; e.g. form input:eq(1) |
:has(seletor) | Поиск элементов содержащих элементы совпадающие с selector; например div:has(p) |
:not(selector) | Поиск элементов несовпадающих с Selector; например div:not(.logo) |
:contains(text) | Поиск элементов содержащих данный текст. Поиск не отличая заглавные или строчные буквы, например p:contains(jsoup) |
:containsOwn(text) | Поиск элементов которые напрямую содержат данный текст |
:matches(regex) | Поиск элементов где текст не совпадает с определенным обычным выражением; например div:matches((?i)login) |
:matchesOwn(regex) | Поиск элементов где текст совпадает с определенным обычным выражением. |
Примечение: Способ индекса pseudo начинается с 0, первый элемент имеет индекс 0, второй элемент имеет индекс 1,.. | |
QueryLinks.java
package org.o7planning.tutorial.jsoup.selector;
import java.io.IOException;
import java.util.Iterator;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class QueryLinks {
public static void main(String[] args) throws IOException {
Connection conn = Jsoup.connect("http://o7planning.org");
Document doc = conn.get();
// Query <a> elements, href contain /document/
String cssQuery = "a[href*=/document/]";
Elements elements= doc.select(cssQuery);
Iterator<Element> iterator = elements.iterator();
while(iterator.hasNext()) {
Element e = iterator.next();
System.out.println(e.attr("href"));
}
}
}Результаты запуска примера:
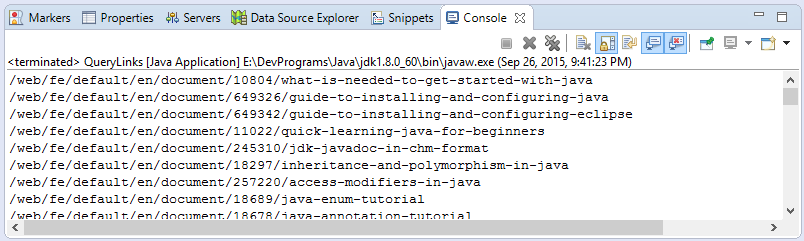
document.html
<html>
<head>
<title>Jsoup Example</title>
</head>
<body>
<h1>Java Tutorial For Beginners</h1>
<br>
<div id="content">
Content ....
</div>
<div class="related-container">
<h3>Related Documents</h3>
<a href="http://o7planning.org/web/fe/default/en/document/649342/guide-to-installing-and-configuring-eclipse">
Guide to Installing and Configuring Eclipse
</a>
<a href="http://o7planning.org/web/fe/default/en/document/649326/guide-to-installing-and-configuring-java">
Guide to Installing and Configuring Java
</a>
<a href="http://o7planning.org/web/fe/default/en/document/245310/jdk-javadoc-in-chm-format">
Jdk Javadoc in chm format
</a>
</div>
</body>
</html>SelectorDemo1.java
package org.o7planning.tutorial.jsoup.selector;
import java.io.File;
import java.io.IOException;
import java.util.Iterator;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class SelectorDemo1 {
public static void main(String[] args) throws IOException {
File htmlFile = new File("document.html");
Document doc = Jsoup.parse(htmlFile, "UTF-8");
// First <div> element has class ="related-container"
Element div = doc.select("div.related-container").first();
// List the <h3>, the direct child elements of the current element.
Elements h3Elements = div.select("> h3");
// Get first <h3> element
Element h3 = h3Elements.first();
System.out.println(h3.text());
// List <a> elements, is a descendant of the current element
Elements aElements = div.select("a");
// Query the current element list.
// The element that href contains 'installing'.
Elements aEclipses = aElements.select("[href*=Installing]");
Iterator<Element> iterator = aEclipses.iterator();
while (iterator.hasNext()) {
Element a = iterator.next();
System.out.println("Document: "+ a.text());
}
}
}Результаты запуска примера:
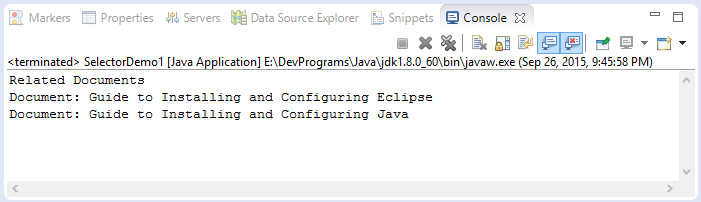
Java Open source libraries
- Руководство Java JSON Processing API (JSONP)
- Использование Scribe OAuth Java API с Google OAuth 2
- Получить информацию об оборудовании в приложении Java
- Restfb Java API для Facebook
- Создание Credentials для Google Drive API
- Руководство Java JDOM2
- Руководство Java XStream
- Использование Java JSoup для анализа кода HTML
- Получение географической информации на основе IP-адреса с помощью GeoIP2 Java API
- Чтение и запись файла Excel в Java с использованием Apache POI
- Изучите Facebook Graph API
- Манипулирование файлами и папками в Google Drive с использованием Java
Show More